No. Entrapeer never uses your data to train, fine-tune, or improve any internal or third-party AI models. Your data, including inputs, outputs, project content, and organizational memory, remains fully owned and controlled by your organization and is used only to generate outputs within your environment. Entrapeer operates with full model and environment isolation. Your deployment runs in a fully isolated environment, either within your VPC or a dedicated tenant. All AI inference is executed using your own LLM API keys, meaning Entrapeer does not use shared or internal model credentials. Customer data is never transmitted to external services for training or reuse. External web search and content retrieval operate in a strictly read-only manner, retrieving publicly available information without sending any customer data outward. This architecture ensures that all AI activity operates entirely under your governance and control.
Your Strategic Intelligence. Your Environment. Your Rules.
Data sovereignty isn't a preference for enterprise, it's a procurement requirement. Every architectural decision we've made is designed to protect the data your strategy depends on.
Compliance and Certifications
Entrapeer is formally pursuing ISO 27001 certification. We do not list a certification until we hold it.
| Certification | Status | Description |
|---|---|---|
| ISO 27001 | In Progress | ISMS formally scoped and structured |
Our Information Security Management System (ISMS) has been formally scoped and designed in alignment with ISO 27001 requirements.
How Entrapeer Protects Your Data?
Five pillars govern every security decision we make.
Data Sovereignty and Privacy
For enterprises in banking, insurance, and regulated industries, where data lives is not a technical preference. It is a compliance requirement and a board-level concern. Entrapeer was architected around this reality from day one.
Data ownership
You own all inputs, outputs, analysis results, and organizational memory generated within your Entrapeer environment.
No cross-client data use
Your data is never used to improve outputs for any other client, anonymized or otherwise.
VPC zero-retention model
In VPC deployments, your data never leaves your infrastructure. Entrapeer has no access to and stores nothing processed in your environment.
Expert interview data
Insights gathered through structured expert interviews within your organization are stored exclusively within your project environment. They are not shared or retained.
Feedback and personalization
When clients provide feedback, Entrapeer uses it to improve personalization within that client's own environment through memory and context.
Core Commitment
Entrapeer does not use your data to train, fine-tune, or improve any AI model. Your inputs, outputs, strategy documents, and organizational memory belong entirely to you.
AI-Specific Security
Deploying an AI system into a regulated enterprise environment introduces security concerns that traditional SaaS vendors do not face. Entrapeer addresses each of them directly.
How Entrapeer eliminates hallucinations
Outputs from Entrapeer's analysis engine are not generated and delivered unchecked. Every project runs through a multi-stage validation pipeline before reaching your team.
Research and sourcing
For each project, the system retrieves and processes more than 10,000 validated sources. Sources are scored algorithmically for domain authority, cross-query frequency, and semantic relevance to the specific strategic question being analyzed.
Reviewer validation
An automated review layer audits every claim in the output, checking for unsupported statements, phantom citations, and speculative content. Claims that cannot be traced to a retrieved, validated source are flagged.
Fixer loop
When issues are detected, a correction layer rewrites, removes, or re-anchors the affected content. This cycle repeats until the reviewer returns a clean status. Zero unsupported claims is the threshold for delivery.
This mechanism is why Entrapeer outputs are described as evidence-linked. Every strategic recommendation your team receives is traceable to a real, verifiable source. This is not a marketing claim. It is an architectural constraint.
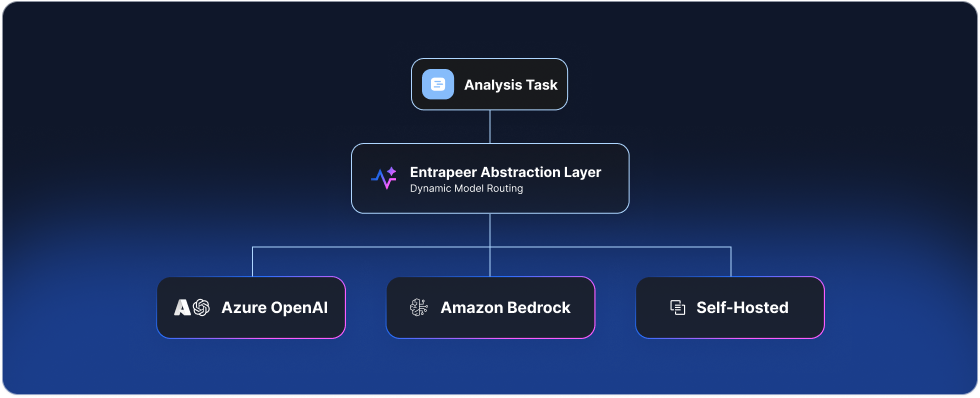
No single AI provider dependency
Entrapeer's architecture does not hard-code a single AI model or provider. We use an abstraction layer that routes each analysis task to the most appropriate model based on reasoning requirements, output type, and your organization's compliance needs. For VPC deployments, clients can plug in their preferred AI providers, including Azure OpenAI, Amazon Bedrock, or self-hosted models. Your organization's AI governance policies, model preferences, and data residency requirements are respected at the infrastructure level.
AI does not make decisions
Entrapeer's outputs are structured strategic intelligence for human decision-makers. The system produces prioritized analyses, evidence-backed roadmaps, and financial projections.
Entrapeer informs and empowers your strategy team. It does not make decisions. Every output is subject to human review before it influences any executive decision. This applies without exception in regulated industries.
Proprietary knowledge base integrity
Entrapeer's core knowledge base contains over 560,000 enterprise use cases and 3 million company profiles. Each record has been cleaned of marketing language and validated against five criteria.
The integrity of this database is maintained by an ongoing expert annotation process and is never updated using client data.
Validation Criteria
AI Governance Alignment
Entrapeer's security and AI governance practices are aligned with the NIST AI Risk Management Framework (NIST AI RMF) and the principles of ISO/IEC 42001. We monitor developments in the EU AI Act for applicability to our enterprise clients in regulated industries.
Infrastructure Security
Entrapeer runs on a cloud-native, containerized microservices architecture. The system was designed for horizontal scale, high availability, and deployment within client-controlled environments.

Architecture principles
Stateless microservices
Each service is independently deployable, stateless, and operates with its own database. No monolithic system handles production data.
Kubernetes orchestration
Runs on Kubernetes with horizontal autoscaling. All services maintain at least two replicas for high availability and fault tolerance.
GitOps deployment
All infrastructure changes are applied via pull-based GitOps. Fully version-controlled, automated, and strictly auditable.
Cloud-agnostic
Deployable across AWS, Azure, and GCP via standard Helm charts. Architectural decisions ensure no strict vendor lock-in.
Automated recovery
Continuous backups combined with 12-hour snapshots allow for full environment recovery without extended downtime.
Secret management
Supports built-in and external key management systems. Integrates natively with client infrastructure policies.
Monitoring and observability
Entrapeer operates a layered monitoring stack covering application performance, infrastructure health, API request lifecycles, and AI reasoning behavior. Anomalies trigger automated alerts and engineering review. Frontend session monitoring ensures UI behavior matches backend performance in real time.

Identity and Access Controls
Entrapeer supports enterprise identity standards out of the box. The following controls are available on all enterprise accounts.
Authentication
SSO and SAML
Single Sign-On (SSO) is supported via SAML 2.0, including Okta and Microsoft Azure AD integration.

SCIM user provisioning
Automated user provisioning and deprovisioning via SCIM 2.0. When a user leaves your organization, access is revoked automatically through your identity provider.
Session management
Session policies and timeout rules are configurable per your organization's security requirements.

Authorization
Role-based access control
Role-based access control (RBAC) is applied across all workspaces. Administrators define roles and permissions at the organization, project, and feature level. Users access only what their role permits. Custom roles can be configured to match your internal governance structure.

Audit Logging & Visibility
In regulated industries, strategy decisions carry accountability. Entrapeer provides a complete audit trail for every action taken within your environment.

Immutable Audit Trails
Every authentication attempt, data access, configuration change, and export is logged in a tamper-evident data store. Logs cannot be modified or deleted, even by administrators.
SIEM Integration
Stream audit events in real-time to your existing security monitoring infrastructure. Native integrations available for New Relic and Grafana.
Retention Policies
Customize log retention periods up to 7 years to meet your specific regulatory requirements. Automatic archiving to cold storage is available for Enterprise clients.
Automated Alerting
Configure real-time alerts for suspicious activity patterns, unauthorized access attempts, or bulk data export events directly within the platform.
Frequently asked questions
Yes. Entrapeer supports both VPC and on-premises deployment models. You can deploy Entrapeer within your own AWS, Microsoft Azure, or Google Cloud environment using Helm charts. For organizations with strict data residency or regulatory requirements, a fully on-premises deployment is also available. In all deployment models, your data remains entirely within your infrastructure, and Entrapeer does not access or control your environment.
Data is always stored and processed within isolated environments. For VPC and on-premises deployments, all data resides entirely within your infrastructure. In the managed platform model, data is stored in a fully isolated, single-tenant environment. Across all deployment options, data is encrypted in transit using TLS and encrypted at rest. There is no shared data layer between customers.
Yes. Entrapeer supports enterprise-grade identity and access management. The platform supports SAML 2.0 Single Sign-On, including integrations with providers such as Okta and Microsoft Azure AD. Multi-factor authentication can be enforced at the organization level. Automated user provisioning and deprovisioning is supported via SCIM 2.0, ensuring that access is automatically revoked when users are removed from your identity provider.
Entrapeer enforces role-based access control across all areas of the platform. Roles can be assigned at the organization, project, and feature levels, ensuring that users only access the resources explicitly permitted by their role. Custom roles can be configured to align with your internal governance and permission structures.
Entrapeer uses a multi-stage validation system to ensure that all outputs are grounded in verified evidence. Every output is audited against supporting sources. Claims that cannot be traced to validated evidence are flagged and removed. A correction layer then refines the output until all claims are fully supported. This process repeats until no unsupported content remains. Each project incorporates more than10,000 validated sources, ensuring outputs are based on evidence rather than assumptions.
No. Entrapeer does not make autonomous decisions. The platform generates structured, evidence-backed strategic intelligence designed to support human decision-makers. Every output is reviewed and validated by your team before influencing any business decision. Entrapeer informs and empowers your organization, but it does not act on your behalf.
Yes. Entrapeer provides full auditability across all platform activity. All user actions are logged with timestamps and user identifiers. Version history is maintained for assumptions, inputs, and outputs. Approval workflows ensure that outputs are reviewed and authorized before being finalized. Audit logs are fully accessible to your administrators and security team.
Ready to stop
rebuilding strategy?
Share one strategic question. We'll show you the logic, the trade-offs, and the execution path yours to own and update.